Notebooks
Reproducible software pipelines
Notebooks, especially Jupyter notebooks, are a very common tool in data science pipelines.
Use with caution!
Problems with notebooks
- Hidden state
- Do not play well with version control
- Encourage making a mess
Hidden state
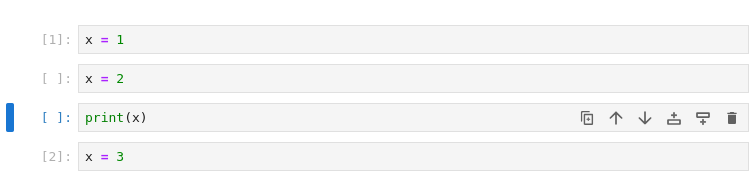
In this case it is rather simple to reconstruct the execution flow, but with long notebooks it becomes nearly impossible. So much that in many cases one dreads restarting the notebook.
Integration with version control
{
"cells": [
{
"cell_type": "code",
"execution_count": 1,
"id": "4cc139ba-137c-4ddc-b966-19f6ac9267c2",
"metadata": {},
"outputs": [],
"source": [
"x = 1"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "66366e84-ab75-405f-b518-125651e814f9",
"metadata": {},
"outputs": [],
"source": [
"x = 2"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "6a70ba6d-875f-4354-877e-f7cbcfda48af",
"metadata": {},
"outputs": [],
"source": [
"print(x)"
]
},
{
"cell_type": "code",
"execution_count": 2,
"id": "70b3bd0e-f5ee-46ef-bdc0-712390b0c12c",
"metadata": {},
"outputs": [],
"source": [
"x = 3"
]
}
],
"metadata": {
"kernelspec": {
"display_name": "Python 3",
"language": "python",
"name": "python3"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.12.4"
}
},
"nbformat": 4,
"nbformat_minor": 5
}Integration with version control
jsonformat → terriblediffs- terrible
diffs → horrible merge conflicts - horrible merge conficts → miserable collaborative experience
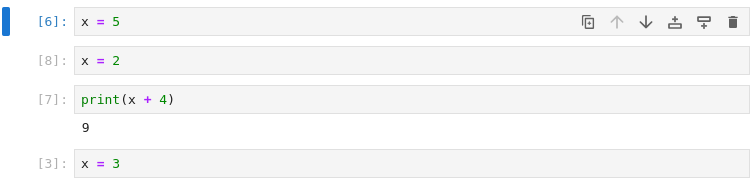
5c5
< "execution_count": 1,
---
> "execution_count": 6,
10c10
< "x = 1"
---
> "x = 5"
15c15
< "execution_count": null,
---
> "execution_count": 8,
25c25
< "execution_count": null,
---
> "execution_count": 7,
28c28,36
< "outputs": [],
---
> "outputs": [
> {
> "name": "stdout",
> "output_type": "stream",
> "text": [
> "9\n"
> ]
> }
> ],
30c38
< "print(x)"
---
> "print(x + 4)"
35c43
< "execution_count": 2,
---
> "execution_count": 3,Notebooks encourage making a mess
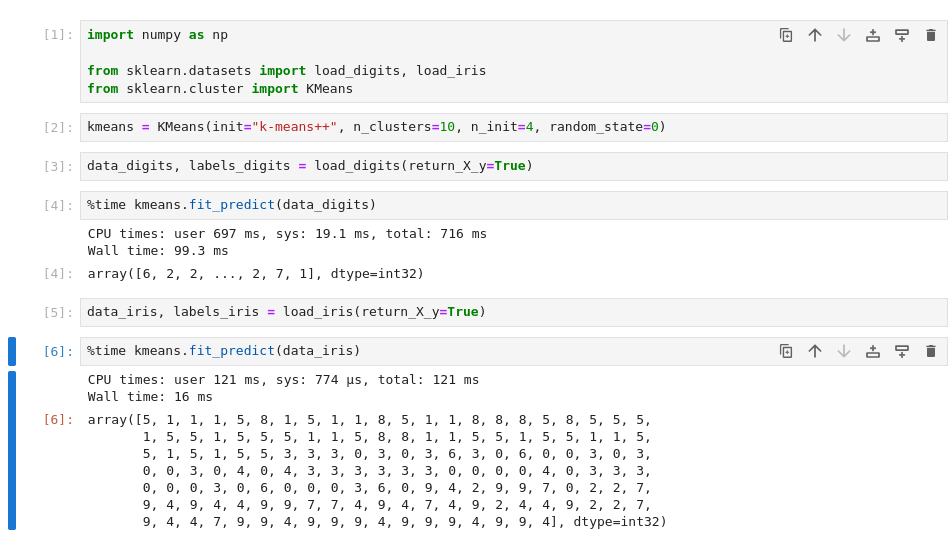
Notebooks encourage making a mess
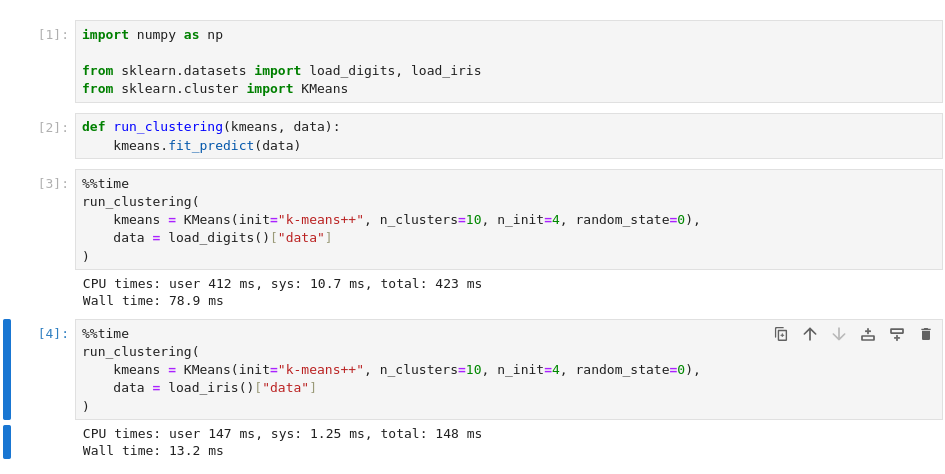
Some solutions: git integration
Many times one has to manage a notebook with git. This tool:
- clears all cell’s outputs
- resets the execution counters

Some solutions: messy code
- Extract all the code to its own Python module
- Import the module in the notebook
- Use only single-line invocations in the notebook
- Use autoreload
- Execute all cells from top to bottom every time (we will deal with efficiency shortly)
- Jupyter notebooks give you a great deal of liberty
- You have to double the effort to keep the code clean and reproducible
Alternatives to Jupyter notebooks
- Quarto (R, Python, Julia, Javascript)
- Pluto (Julia)
- Observable (Javascript)
- Streamlit (Python)
- Marimo (Python)
- Shiny (R)
Quarto
- Write documents in Markdown
- Code cells are executed
- Whenever you render the document all cells are executed top-to-bottom
- Supports a lot of languages
Pluto
- Has a web interface just like Jupyter
- Cells are reactive: upon modification all cells that depend on modified values are re-executed
- Only supports Julia
Observable
- Has a hosted online notebook environment
- Reactive cells
- Only supports Javascript
- Great for interactive client-side graphics
Streamlit
- You write a Python script using the streamlit library to present content
- The script execution results in a web application
- Limited to Python
Shiny
- Similar to Streamlit
- Supports both R and Python